
The latest research out of Facebook sets machine learning models to tasks that, to us, seem rather ordinary — but for a computer are still monstrously difficult. These projects aim to anonymize faces, improvise hand movements, and — perhaps hardest of all — give credible fashion advice.
The research here was presented recently at the International Conference on Computer Vision, among a few dozen other papers from the company, which has invested heavily in AI research, computer vision in particular.
Modifying faces in motion is something we’ve all come to associate with “deepfakes” and other nefarious applications. But the Facebook team felt there was actually a potentially humanitarian application of the technology.
Deepfakes use a carefully cultivated understanding of the face’s features and landmarks to map one person’s expressions and movements onto a completely different face. The Facebook team used the same features and landmarks, but instead uses them to tweak the face just enough that it’s no longer recognizable to facial recognition engines.
This could allow someone who, for whatever reason, wants to appear on video but not be recognized publicly to do so without something as clunky as a mask or completely fabricated face. Instead, they’d look a bit like themselves, but with slightly wider-set eyes, a thinner mouth, higher forehead, and so on.

The system they created appears to work well, but would of course require some optimization before it can be deployed as a product. But one can imagine how useful such a thing might be, either for those at risk of retribution from political oppressors or more garden variety privacy preferences.
In virtual spaces it can be difficult to recognize someone at all — partly because of the lack of nonverbal cues we perceive constantly in real life. This next piece of research attempts to capture, catalogue, and reproduce these movements, or at least the ones we make with our hands.
It’s a little funny to think about, but really there’s not a lot of data on how exactly people move their hands when they talk. So the researchers recorded 50 full hours of pairs of people having ordinary conversations — or as ordinary as they could while suited up in high-end motion capture gear.
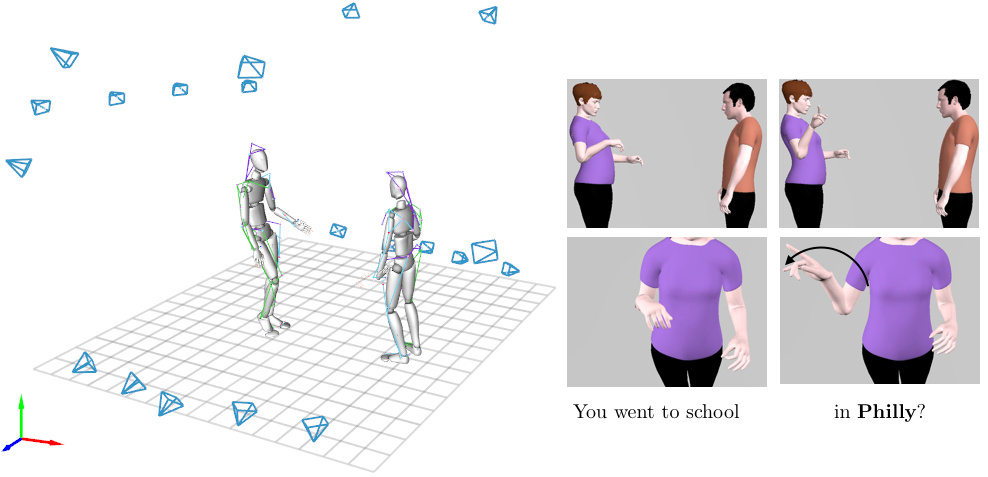
These (relatively) natural conversations, and the body and hand motions that went with them, were then ingested by the machine learning model; it learned to associate, for example, that when people said “back then” they’d point behind them, or when they said “all over the place,” they’d make a sweeping gesture.
What might this be used for? More natural-seeming conversations in virtual environments, perhaps, but maybe also by animators who’d like to base the motions of their characters in real life without doing motion capture of their own. It turns out that the database Facebook put together is really like nothing else out there in scale or detail, which is valuable in and of itself.
Similarly unique, but arguably more frivolous, is this system meant to help you improve your outfit. If we’re going to have smart mirrors, they ought to be able to make suggestions, right?
Fashion++ is a system that, having ingested a large library of images labeled with both the pieces worn (e.g. hat, scarf, skirt) and overall fashionability (obviously a subjective measure), can then look at a given outfit and suggest changes. Nothing major — it isn’t that sophisticated — but rather small things like removing a layer or tucking in a shirt.

It’s far from a digital fashion assistant, but the paper documents early success in making suggestions for outfits that real people found credible and perhaps even a good idea. That’s pretty impressive given how complex this problem proves to be when you really consider it, and how ill-defined “fashionable” really is.
Facebook’s ICCV research shows that the company and its researchers are looking fairly broadly at the question of what computer vision can accomplish. It’s always nice to detect faces in a photo faster or more accurately, or infer location from the objects in a room, but clearly there are many more obscure or surprising aspects of digital life that could be improved with a little visual intelligence. You can check out the rest of the papers here.











